You can use Pandas for random sampling of Datasets
The sample method in Pandas is a convenient way to randomly select rows or samples from a DataFrame or Series object. By default, the method returns a random sample of the same size as the original data, but you can specify a different sample size by passing the n parameter.
There are a few other parameters that can be used to customize the random sampling:
weights: specify a weight for each row in the data that will be used to determine the probability of a row being included in the sample.
replace: specify whether the sampling should be done with or without replacement. If replace=False, each row will be selected only once. If replace=True, a row can be selected multiple times.
random_state: specify a seed value for the random number generator to ensure that the results are reproducible.
Here’s an example to illustrate the usage of the sample method:
import pandas as pd
df = pd.DataFrame({'col1': [1, 2, 3, 4, 5],
'col2': [6, 7, 8, 9, 10]})
# generate a random sample of size 3 from the dataframe
df.sample(n=3, random_state=42) col1 col2
1 2 7
0 1 6
4 5 10This will return a new DataFrame with 3 randomly selected rows from the original DataFrame.
An example of how you can use the sample method in Pandas with a real-world dataset from a library:
import pandas as pd
import seaborn as sns
# Load the Titanic dataset from the seaborn library
titanic = sns.load_dataset('titanic')
print(titanic)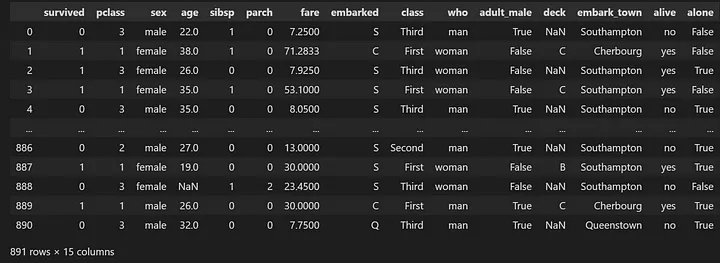
# Generate a random sample of size 100 from the Titanic dataset
sample = titanic.sample(n=100, random_state=42)
# Analyze the sample
print("Sample mean age:", sample['age'].mean())
print("Sample survival rate:", sample['survived'].mean())This code loads the Titanic dataset using the sns.load_dataset function from the seaborn library, generates a random sample of size 100 from the data, and calculates the mean age and survival rate for the sample. The random_state parameter is set to 42 to ensure that the results are reproducible.
Note that this is just a simple example to illustrate how the sample method can be used in real-world data analysis. In practice, you would likely perform more complex analyses on the data, such as visualizing the distributions of different variables or building predictive models.
Yes, one important thing to keep in mind when using the sample method is that it can be computationally expensive for large datasets. This is because the method needs to randomly select rows from the entire data, which can be time-consuming for large datasets. In such cases, it may be more efficient to randomly select a smaller subset of the data and work with that, or to use techniques such as stratified sampling to ensure that the sample represents the entire population.
Another thing to keep in mind is that the sample method is not suitable for all types of data analysis. For example, if you’re working with time-series data, you may need to use a different method for selecting a sample, such as random sampling with a time-based offset.
Finally, it’s important to be mindful of the potential for sampling bias when using the sample method. This can occur if the sample is not representative of the entire population, which can happen if the sample is not selected randomly or if the sample size is too small. To reduce the risk of sampling bias, it’s important to ensure that the sample is large enough to accurately represent the population, and to use techniques such as stratified sampling to ensure that the sample is representative of the entire population.
One more example of how you can use the sample function to balance an imbalanced dataset:
import pandas as pd
import numpy as np
# Create a sample dataset
data = {'class': [0, 0, 0, 1, 1, 1, 1, 1, 1]}
df = pd.DataFrame(data)
# Get the size of the majority class
majority_class_size = df[df['class'] == 1].shape[0]
# Randomly select a subset of the minority class data to balance the class distribution
minority_class = df[df['class'] == 0]
sample_minority_class = minority_class.sample(n=majority_class_size, replace=True, random_state=np.random.seed(42))
# Concatenate the minority class data and the balanced sample data
balanced_df = pd.concat([sample_minority_class, df[df['class'] == 1]])
print(balanced_df) class
3 1
4 1
5 1
6 1
7 1
8 1
0 0
2 0
0 0In this example, we create a sample dataset with a binary classification problem and a highly imbalanced class distribution. We use the sample function to randomly select a subset of the minority class data to balance the class distribution. The replace parameter in the sample function allows us to sample with replacement, so we can sample the same data point multiple times if needed to balance the class distribution. The random_state parameter allows us to set the seed for the random number generator, so we can get the same results every time we run the code.
The sample function in Pandas can be used in a variety of situations where you need to select a random subset of data from a larger dataset. Some common use cases include:
- Exploratory data analysis: when you want to get a quick understanding of the distribution of different variables in a large dataset, you can use the
samplefunction to randomly select a subset of the data and analyze that instead of the entire dataset. - Model evaluation: when you’re building a machine learning model, you may want to use a random sample of the data to evaluate the model’s performance. This can be useful for testing the model’s accuracy without using the entire dataset, which can be time-consuming or computationally expensive.
- Data visualization: when you want to visualize the distribution of a large dataset, you can use the
samplefunction to randomly select a subset of the data to plot instead of the entire dataset. This can help to reduce the risk of overloading the memory or slowing down the plotting process for very large datasets. - Bootstrapping: the
samplefunction can be used as part of a bootstrapping procedure, where you generate multiple random samples from a dataset to estimate the distribution of a statistic, such as the mean or standard deviation. - Monte Carlo simulations: when you’re running Monte Carlo simulations, you may want to use the
samplefunction to randomly select input data for each simulation.

#Artificial Intelligence
#Beginners Guide
#Machine Learning
#AI
#Pandas