
L1 and L2 regularization are methods implemented to combat overfitting in predictive models by modifying the loss function with a penalty component. L1 regularization, often referred to as Lasso, incorporates a term based on the absolute values of the model’s weight coefficients. Conversely, L2 regularization, known as Ridge regularization, involves a term based on the squared values of the weights. The primary purpose of these approaches is to constrain the weight coefficients, nudging them closer to zero, which helps in reducing overfitting and enhancing the model’s ability to generalize to new data.
L1 regularization, also known as Lasso regularization, adds a term to the loss function that is proportional to the absolute value of the weight coefficients. Mathematically, it can be represented as:
L1 regularization term = λ * ∑|wi|
Where λ is the regularization parameter, which controls the strength of the regularization, and wi are the weight coefficients of the model. The L1 regularization term is added to the original loss function, such as mean squared error, to form the new loss function.
On the other hand, L2 regularization, also known as Ridge regularization, adds a term to the loss function that is proportional to the square of the weight coefficients. Mathematically, it can be represented as:
L2 regularization term = λ * ∑wi²
Where λ is the regularization parameter, and wi are the weight coefficients of the model. Similar to L1 regularization, the L2 regularization term is added to the original loss function to form the new loss function.
An example of how L2 regularization can help prevent overfitting is in linear regression. Without L2 regularization, the model could fit the training data perfectly by assigning high weight coefficients to all the features. However, these high weight coefficients would result in poor generalization to new data, as the model would be too complex. By adding an L2 regularization term, the model is forced to assign relatively small weight coefficients to all the features, which leads to a simpler model and better generalization.
The key difference between L1 and L2 regularization is that L1 regularization will shrink some of the weight coefficients to zero, effectively selecting a subset of the most important features, while L2 regularization will shrink all the weight coefficients but none of them will become zero.
It’s also worth noting that in practice, L1 and L2 regularization are often combined to form the Elastic-Net regularization which is a linear combination of both L1 and L2 regularization.
Let’s consider a simple linear regression problem with two features, x1 and x2. Without regularization, the model would be represented by the equation:
y = w1 * x1 + w2 * x2 + b
Where y is the target variable, x1 and x2 are the input features, w1 and w2 are the weight coefficients, and b is the bias term.
Now, let’s say we have a dataset with 100 samples, and the model has a high variance (overfitting) and doesn’t generalize well to new data. We can use L1 regularization to penalize large weight coefficients and force them to be closer to zero. The new loss function with L1 regularization would be:
Loss = MSE(y, y_pred) + λ * (|w1| + |w2|)
Where MSE is the mean squared error, y_pred is the predicted value, and λ is the regularization parameter that controls the strength of the regularization.
By adding this L1 regularization term to the loss function, the model is forced to assign relatively small weight coefficients to x1 and x2, which leads to a simpler model and better generalization.
Similarly, if we use L2 regularization, the new loss function will be:
Loss = MSE(y, y_pred) + λ * (w1² + w2²)
By adding this L2 regularization term, the model is forced to assign relatively small weight coefficients to x1 and x2, which leads to a simpler model and better generalization.
In both cases, the regularization parameter λ can be adjusted to control the balance between fitting the training data well and keeping the model simple. A larger λ will result in smaller weight coefficients and a simpler model, while a smaller λ will allow for larger weight coefficients and a more complex model.
It’s worth noting that regularization is just one of many techniques to prevent overfitting and it should be used in conjunction with other techniques such as cross-validation, early stopping, and Dropout.
L1 regularization uses Manhattan distances to arrive at a single point, so there are many routes that can be taken to arrive at a point. L2 regularization uses Euclidean distances, which will tell you the fastest way to get to a point. This means the L2 norm only has 1 possible solution.
Since L2 regularization takes the square of the weights, it’s classed as a closed solution. L1 involves taking the absolute values of the weights, meaning that the solution is a non-differentiable piecewise function or, put simply, it has no closed form solution. L1 regularization is computationally more expensive, because it cannot be solved in terms of matrix math.
Here’s an example of how to use L1 regularization (also known as Lasso regularization) in Python with the scikit-learn library:
from sklearn.linear_model import Lasso
from sklearn.datasets import make_regression
# Generate a synthetic dataset
X, y = make_regression(n_samples=100, n_features=10, random_state=42)
# Create a Lasso model with a regularization parameter of 0.1
lasso = Lasso(alpha=0.1)
# Fit the model to the data
lasso.fit(X, y)
# Print the weight coefficients
print(lasso.coef_)In this example, we first generate a synthetic dataset with 100 samples and 10 features using the make_regression function from scikit-learn. Then, we create a Lasso model with a regularization parameter of 0.1 (alpha=0.1) and fit it to the data using the fit() method. The weight coefficients of the model can be accessed using the coef_ attribute.
Now, Here’s an example of how to use L2 regularization (also known as Ridge regularization) in Python with the scikit-learn library:
from sklearn.linear_model import Ridge
from sklearn.datasets import make_regression
# Generate a synthetic dataset
X, y = make_regression(n_samples=100, n_features=10, random_state=42)
# Create a Ridge model with a regularization parameter of 0.1
ridge = Ridge(alpha=0.1)
# Fit the model to the data
ridge.fit(X, y)
# Print the weight coefficients
print(ridge.coef_)In this example, we first generate a synthetic dataset with 100 samples and 10 features using the make_regression function from scikit-learn. Then, we create a Ridge model with a regularization parameter of 0.1 (alpha=0.1) and fit it to the data using the fit() method. The weight coefficients of the model can be accessed using the coef_ attribute.
It’s important to note that the regularization parameter (alpha) is a hyperparameter that must be tuned using techniques such as cross-validation to find the best value for a specific dataset and model.
You can also use Elastic-Net regularization by using ElasticNet class in scikit-learn library, which is the combination of L1 and L2 regularization.
from sklearn.linear_model import ElasticNet
# Create an ElasticNet model with a regularization parameter of 0.1 and l1_ratio of 0.5
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
# Fit the model to the data
elastic_net.fit(X, y)
# Print the weight coefficients
print(elastic_net.coef_)You can use L1 and L2 regularization in Keras by using the kernel_regularizer or activity_regularizer arguments when creating a layer.
Here’s an example of how to use L1 regularization (also known as Lasso regularization) in a Keras model:
from keras import regularizers
from keras.layers import Dense
from keras.models import Sequential
# Create a sequential model
model = Sequential()
# Add a dense layer with L1 regularization
model.add(Dense(10, input_shape=(10,), kernel_regularizer=regularizers.l1(0.01), activation='relu'))
# Add more layers as necessary
# Compile the model
model.compile(optimizer='adam', loss='mean_squared_error')In this example, we create a sequential model and add a dense layer with L1 regularization using the kernel_regularizer argument. The regularization parameter is set to 0.01 (l1(0.01)) and the activation function is set to ‘relu’.
Here’s an example of how to use L2 regularization (also known as Ridge regularization) in a Keras model:
from keras import regularizers
from keras.layers import Dense
from keras.models import Sequential
# Create a sequential model
model = Sequential()
# Add a dense layer with L2 regularization
model.add(Dense(10, input_shape=(10,), kernel_regularizer=regularizers.l2(0.01), activation='relu'))
# Add more layers as necessary
# Compile the model
model.compile(optimizer='adam', loss='mean_squared_error')In this example, we create a sequential model and add a dense layer with L2 regularization using the kernel_regularizer argument. The regularization parameter is set to 0.01 (l2(0.01)) and the activation function is set to ‘relu’.
You can also use Elastic-Net regularization by using l1_l2 regularizer. In this case, you’ll need to pass both l1 and l2 regularization values.
from keras import regularizers
from keras.layers import Dense
from keras.models import Sequential
# Create a sequential model
model = Sequential()
# Add a dense layer with Elastic-Net regularization
model.add(Dense(10, input_shape=(10,), kernel_regularizer=regularizers.l1_l2(l1=0.01, l2=0.01), activation='relu'))
# Add more layers as necessary
# Compile the model
model.compile(optimizer='adam', loss='mean_squared_error')It’s important to note that the regularization parameter (alpha) is a hyperparameter that must be tuned using techniques such as cross-validation to find the best value for a specific dataset and model.
It’s also worth noting that in case of using activity regularizer, it will be applied on the output of the layer.
It is difficult to produce images or graphs, but I can describe the expected changes on a graph roughly based on my experience
For example, to visualize the effect of L1 regularization on a linear regression model, you can plot the weight coefficients of the model as a function of the regularization parameter. Without regularization, the weight coefficients will be relatively large and will not be sparse(not many of them will be zero), and the model will be overfitting the training data. As the regularization parameter increases, the weight coefficients will become smaller, and more of them will be zero, resulting in a simpler model that generalizes better to new data.
Another way to visualize the effect of L1 regularization is by plotting the training and validation loss as a function of the regularization parameter. As the regularization parameter increases, the weight coefficients will become smaller, resulting in a simpler model that generalizes better to new data. As a result, the validation loss will decrease, and the training and validation loss will converge.
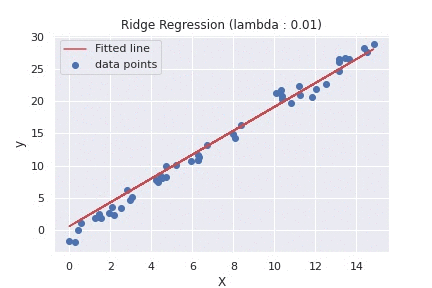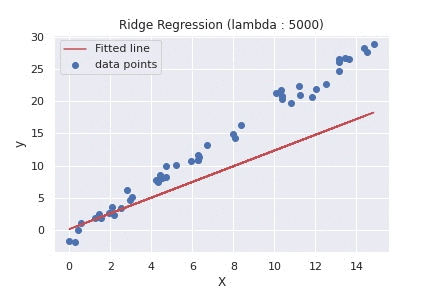
— — — — — — –different values of L2 affect the Regression line. — — — —
For L2 regularization, you can plot the weight coefficients of the model as a function of the regularization parameter. Without regularization, the weight coefficients will be relatively large and the model will be overfitting the training data. As the regularization parameter increases, the weight coefficients will become smaller and converge to non-zero values, resulting in a simpler model that generalizes better to new data.
It’s worth noting that the best way to understand the effect of regularization is to experiment with different regularization parameters on your own dataset and see how it affects the model’s performance.
In summary,
L1 and L2 regularization work by adding a penalty term to the loss function based on the weight coefficients of the neurons in the model. This helps to prevent overfitting by shrinking the weight coefficients towards smaller values and in case of L1 towards zero.
The differences between L1 and L2 regularization:
- L1 regularization penalizes the sum of absolute values of the weights, whereas L2 regularization penalizes the sum of squares of the weights.
- The L1 regularization solution is sparse. The L2 regularization solution is non-sparse.
- L2 regularization doesn’t perform feature selection, since weights are only reduced to values near 0 instead of 0. L1 regularization has built-in feature selection.
- L1 regularization is robust to outliers, L2 regularization is not.
I hope this helps! Let me know if you have any more questions.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
#Data Science
#Artificial Intelligence
#Beginners Guide
#Machine Learning
#Machine Learning Ai