Artificial intelligence (AI) models have seen remarkable progress in recent years, with models like GPT-3 and PaLM showing human-level performance on many language tasks. However, the compute required to train these massive models is prohibitive, making further progress difficult.
Enter Mixture of Experts (MoE), an AI architecture that enables dramatically more efficient training of large-scale models. MoEs could be the key that unlocks the next level of AI capability.

In this guide, we’ll cover:
- What Exactly Are Mixture of Experts Models
- The Origins and Evolution of MoEs
- How MoEs Enable Efficient Training at Scale
- Unique Properties and Tradeoffs of MoE Models
- Open Challenges for MoE Training and Inference
- Exciting Recent Innovations to Make MoEs Faster
- Promising Directions for MoE Research
Let’s dive in and explore the past, present, and future of this highly promising AI technique!
What Exactly Are Mixture of Expert Models?
Mixture of experts refers to neural network architectures where a model is composed of many smaller “expert” modules, instead of one massive dense network.
Specifically in transformers, the key components of a MoE model are:
- Sparse MoE layers: Instead of using huge feedforward layers, smaller expert modules are used. Each expert specializes in processing certain inputs.
- Gating/routing network: This component assigns different parts of the input to different experts. For example, a “dates” expert may process all date tokens.
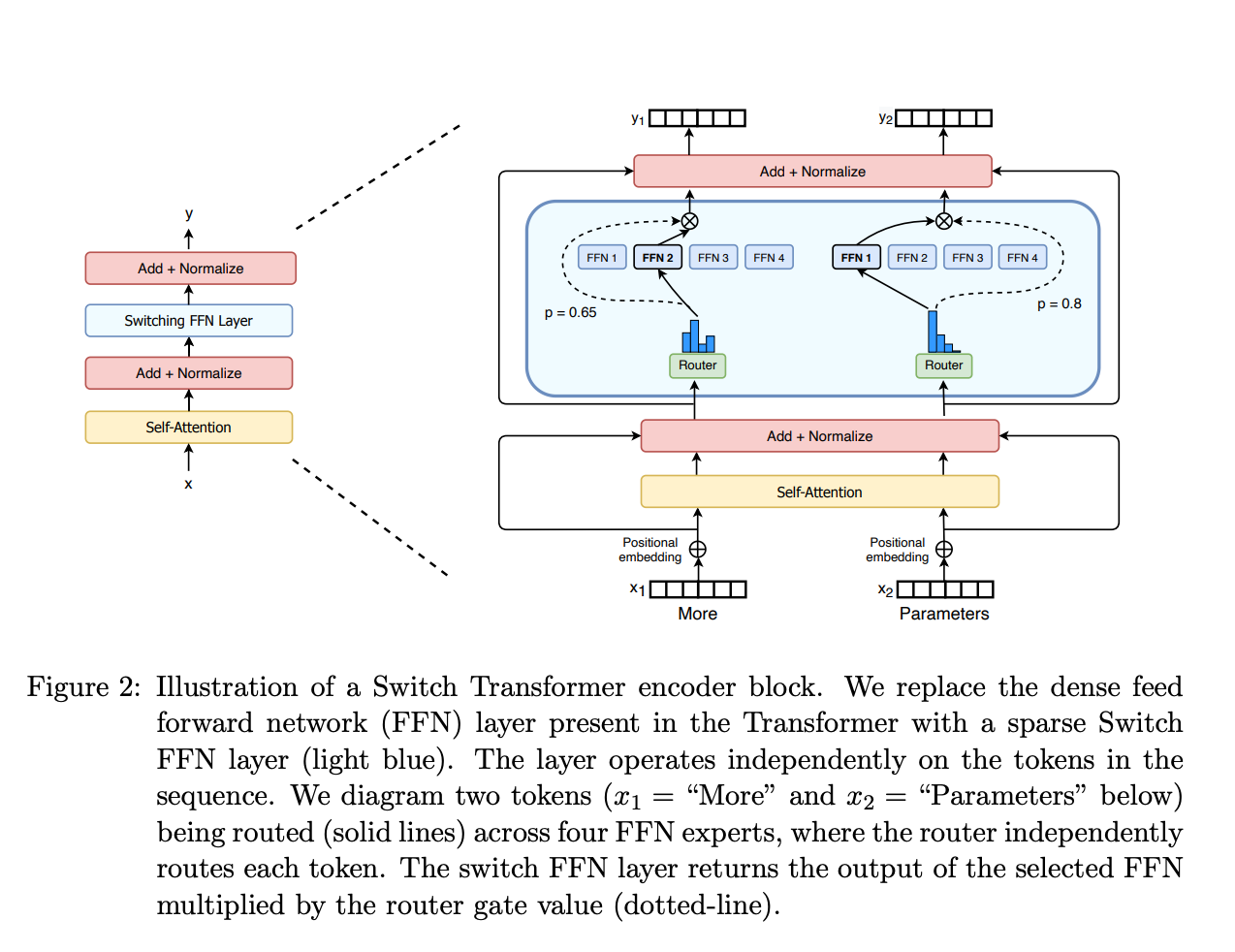
This enables dramatically more efficient training, as experts can be updated in parallel across many devices. The same model quality can be reached with far less compute compared to dense networks.
For inference, only experts that were activated need to run. So we retain the benefits of a huge model, with lower memory and compute costs.
Now that we have an overview, let’s look at the research history that brought us this innovation.
The Origins and Evolution of Mixture of Experts
The conceptual foundation for MoEs was established back in the early 90’s, but only recently has progress in deep learning made MoEs practical for large NLP models.
Early Exploration of Modular and Efficient Networks
The seminal 1991 paper “Mixture of Experts” proposed having multiple separate models coordinated by a gating network. Each model would specialize on certain input regions.
Later work explored integrating expert-like modules into larger deep networks. For example, conditional computation focused on dynamically activating parts of networks per input.
These concepts eventually led to experts being used as components within transformer models.
Sparsely-Gated Experts for Machine Translation
In 2017, Noam Shazeer and collaborators scaled LSTM machine translation models to 137 billion parameters using sparsely activated mixture of experts layers.
This greatly increased model scale while keeping training efficient and inference fast. However it faced challenges like expert capacity under-utilization and training instability.
Nevertheless this pioneering work showed the promise of MoE-based scaling, setting the stage for optimization.
Evolution to Trillion-Scale Models
Later work like GShard (2022) integrated MoE layers into transformers, using innovations like random expert routing and expert capacity limits to improve scaling.
The 1.6 trillion parameter Switch Transformer model (2022) made key optimizations like simplified single-expert routing per token to boost stability.
Thanks to such optimizations, MoEs can now efficiently scale to trillions of parameters for state-of-the-art results.
How MoEs Enable Efficient Training at Scale
We’ve seen how MoEs evolved over time. But what specifically makes them so efficient compared to dense models?
There are a few key properties of MoE designs that enable massive gains in computational efficiency:
Conditional computation — For any given input, only a small subset of experts are active. Computation is focused on relevant parts of the model, rather than spreading across a huge dense network.
Expert parallelism — Experts can be placed on separate devices and updated in parallel. This multiplies total throughput for training.
Reduced communication — With single-expert routing, less coordination is needed between devices compared to more complex schemes.
Specialization — Experts gradually specialize for certain inputs over training. Each expert can overfit less and learn more efficiently as a result.
Together, these attributes make it possible to achieve cutting-edge model quality with 1/10th the computation of dense transformers.
However, there are also unique training and inference challenges…
Unique Properties and Tradeoffs of MoE Models
While providing massive efficiencies, properties like sparisty and specialization also pose new difficulties when working with MoEs:
Generalization — Specialized experts can struggle to handle diverse data, risking poorer performance after deployment. Careful routing algorithms and training techniques are needed.
Training stability — Sparse connectivity and expert imbalances can destabilize optimization. Solutions like router Z-loss help prevent instability.
Memory costs — Although efficient for computation, all experts and their connections still need to be stored, requiring high memory. Compression after training can help.
Hyperparameter differences — Unique properties like expert specialization mean different hyperparameters work best for MoEs when fine tuning compared to dense networks.
Despite these challenges, recent work has made good progress — enough to make MoEs a viable path forward for state-of-the-art AI systems.
And ongoing research is rapidly improving MoE training efficiency and overcoming limitations…
Exciting Recent Innovations to Make MoEs Faster
Much work has gone into optimizing MoE training, given the very high computational costs involved at trillion-parameter scale.
Here are some examples of impactful recent innovations:
Load balancing innovations — Techniques like router Z-loss stabilize training, while balanced token routing and expert capacity limits prevent overload.
Efficient parallelism — Approaches like FasterMoE (2022) customize interconnect topologies, communication protocols and more for optimized MoE parallelism.
Sparse compute kernels — MegaBlocks (2022) provides custom GPU kernels to efficiently handle dynamic sparse MoE routing and uneven load balancing.
Quantization — Q-MoE (2023) applies weight quantization to enable over 75x memory compression with minimal quality loss, for much faster loading and inference.
Thanks to advanced work like this, training today’s largest MoE models is becoming highly practical. Next we’ll look at where research is headed next!
Promising Directions for MoE Research
Mixture of expert models have come a long way in just a few years. But there are still many open questions to explore as this area of research continues evolving rapidly.
Here are some promising directions for pushing MoE capabilities even further:
Multi-task learning — By training one model on many tasks at once, utilizing expert specialization for each task, overall performance and efficiency can be improved.
Model distillation — Distilling the knowledge of a MoE model into a smaller dense model retains much of the quality, while enabling faster and cheaper deployment.
Hierarchical mixtures — Stacking MoE layers in deep hierarchies, with higher-level gating networks controlling lower-level experts, is largely unexplored but holds promise.
Dynamic architectures — Rather than fixed structures, enabling models to dynamically allocate experts over time could maximize both efficiency and capability.
As solutions to challenges like stability, training efficiency and serving costs are developed through innovations like the above, extremely large MoE models will become more and more viable and transformative.
The future is bright for this burgeoning approach to scalable AI!
Conclusion
Mixture of expert models represent a paradigm shift in how we can build and scale AI systems for the future. By composing models out of many specialized modules instead of monolithic networks, we can slash the computational burden while reaching new heights of intelligence.
In this guide we covered the origins of MoEs, how they enable efficient training, unique tradeoffs to be aware of, and recent optimizations that point the way forward.
It’s an exciting time for this rapidly evolving field! MoEs overcome critical barriers for AI progress, potentially unlocking a new level of beneficial, safe and ethical advanced intelligence.