
HuggingFace’s Mixtral integration
“ Mixtral 8x7b ” is an exciting LLM released today by “Mistral”. We established a new open-model SoTA that outperforms GPT-3.5 across many benchmarks.
The Mistral integrations for HuggingFace delivered today include:
・Model sharing on HuggingFace Hub
・Integration with Transformrs
・Integration with Inference Endpoint
・Integration with Text Gemeration Inferenct
・Fine tuning with TRL
2. Mixtral 8x7b
2–1. Mixtral 8x7b
Mixtral has a similar architecture to Mistral 7B, but with a twist . Eight “expert” models are combined into one using a technology called “ MoE “ (Mixture of Experts). For Tranformer models, the way this works is to replace some feedforward layers with sparse MoE layers. The MoE layer also includes a network of routers to choose which experts handle which tokens most efficiently. In the case of Mixtral, two experts are selected for each time step, so it can decode at the speed of a model with a parameter density of 12B, despite having four times the number of effective parameters.
2–2. Features of Mixtral 8x7b
・Release of base model and instruction model
・Supports context length of 32k tokens
・Exceeds Llama2–70B and matches or exceeds GPT-3.5 in most benchmarks
・Supports English, French, German, Spanish, Italian
Good at correspondence and coding, 40.2% in HumanEval
, commercially available with Apache 2.0 license
2–3. Moe

2–4. Evaluation
Below is a performance comparison of the base model and other open models on the “LLM Leaderboard” (higher scores are better).
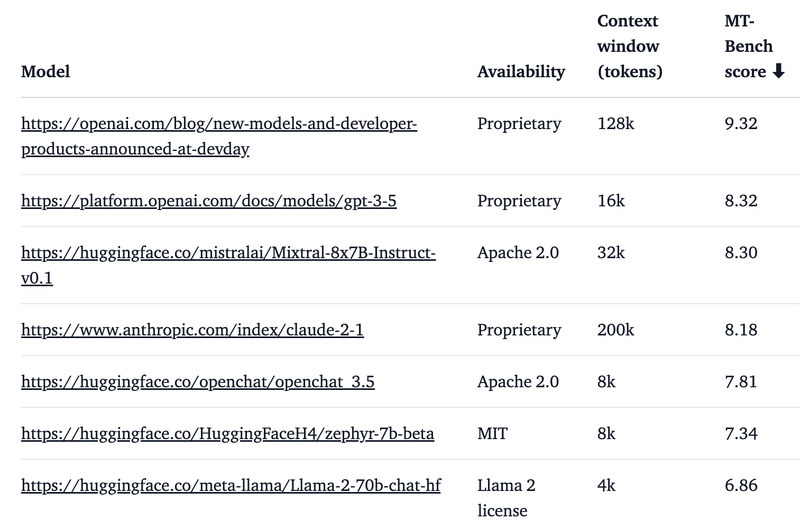
Below is a comparison of “Mixtral Instruct” and “MT-Bench” and “AlpacaEval” in closed and open models (the higher the score, the better).
“Mixtral Instruct” outperforms all other open models on “MT-Bench” and becomes the first model to achieve performance comparable to “GPT-3.5”.
2–5. Model size
“Mixtral MoE” is called “Mixtral-8x7B”, but there is no 56B parameter. Shortly after release, we discovered that some people were under the misconception that the model behaved similarly to an ensemble of 8 models with 7B parameters each, but the “MoE” model did not.
Only some layers of the model (feedforward blocks) are replicated. The remaining parameters are the same as the 7B model. The total number of parameters is about 45B, not 56B . There could have been a better name to better convey the architecture.
2–6. Prompt format
The base model has no prompt format.
The instruction model has a very simple prompt format.
<s> [INST] User Instruction 1 [/INST] Model answer 1</s> [INST] User instruction 2[/INST]2–7. Unresolved questions
As with the previous “Mistral 7B”, there are some unanswered questions about this new model. In particular, there is no information about the size of the dataset used for pretraining, its composition, or how it was preprocessed. Similarly, for the ‘Mixtral’ instruction model, no details regarding fine-tuning datasets or hyperparameters related to ‘SFT’ and ‘DPO’ were shared.
3. Demo
You can chat with the “Mixtral” instruction model on “HuggingFace Chat”.
HuggingChatThe first open source alternative to ChatGPT. 💪huggingface.co
4. Inference
There are two main ways to perform inference in Mixtral.
・Transformers の pipeline()
・Text Generation Inference
Each method allows you to run the model with half precision (float16) or quantized weights. Since the size of the “Mixtral” model is approximately equivalent to the 45B parameter dense model, the minimum size of VRAM required can be estimated as follows:
・float16 > 90GB
・8bit > 45GB
・4bit > 23GB
5. Integration with Transformers
With Transformers v4.36, Mixtral lets you leverage all the tools in the HuggingFace ecosystem.
・Training and inference scripts and examples
・safetensors
・Tools such as bitsandbytes, PEFT, Flash Attendant 2
・Text generation utilities and helpers
・Mechanisms to export models for deployment
pip install -U "transformers==4.36.0" --upgradeThe code below shows how to perform inference with Transformers and 4bit quantization. Due to the large model size, it requires at least 30GB of RAM to run.
from transformers import AutoTokenizer
import transformers
import torch
model = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])<s>[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST] A Mixture of Experts is an ensemble learning method that combines multiple models, or "experts," to make more accurate predictions. Each expert specializes in a different subset of the data, and a gating network determines the appropriate expert to use for a given input. This approach allows the model to adapt to complex, non-linear relationships in the data and improve overall performance.6. Integration with Text Generation Inference
“Text Generation Inference” is a production-ready inference container by HuggingFace. Deploying LLM is easy. Features include continuous batch processing, token streaming, Tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
For more information on how to deploy LLM using the HuggingFace inference endpoint, see the article .
7. Fine tuning with TRL
Learning an LLM can be both technically and computationally challenging. This section describes the tools available in the HuggingFace ecosystem to efficiently train Mixtral on a single A100 GPU.
Below is an example command to fine-tune Mixtral with the OpenAssistant chat dataset. To save memory, we utilize 4bit quantization and QLoRA to target all linear layers within the Attention block. Note that you should not target MLP layers, as unlike dense Transformers, MLP layers are sparse and do not interact well with PEFT.
First, install the nightly version of TRL and clone the repository to access the learning scripts .
pip install -U transformers
pip install git+https://github.com/huggingface/trl
git clone https://github.com/huggingface/trl
cd trlThen run the script.
accelerate launch --config_file examples/accelerate_configs/multi_gpu.yaml --num_processes=1 \
examples/scripts/sft.py \
--model_name mistralai/Mixtral-8x7B-v0.1 \
--dataset_name OpenAssistant/oasst_top1_2023-08-25 \
--batch_size 2 \
--gradient_accumulation_steps 1 \
--learning_rate 2e-4 \
--save_steps 20_000 \
--use_peft \
--peft_lora_r 16 --peft_lora_alpha 32 \
--target_modules q_proj k_proj v_proj o_proj \
--load_in_4bitTraining on a single A100 takes approximately 9 hours, but can be easily parallelized by adjusting — num_processes to the number of available GPUs.
8. Disclaimer and Work in Progress
8–1. Quantization
Quantization of MoE is an active research area. TheBloke made initial experiments to achieve 4bit and 8bit quantization, but the quality of the model decreased significantly. I’m very excited to see developments in this area in the coming days and weeks. Additionally, recent research such as QMoE, which achieves sub-1bit quantization of MoE, can also be applied here.
8–2. High VRAM usage
MoE runs inference very fast, but still requires large amounts of VRAM (and therefore expensive GPUs). This makes it difficult to use in local settings. MoE is ideal for setups with many devices and large amounts of VRAM. “Mixtral” requires 90GB of VRAM in half precision.