A Unified Transformer for Multimodal Understanding and Generation

Introduction
“The best way to predict the future is to invent it.”-Alan Kay
The field of artificial intelligence (AI) is witnessing a rapid evolution, particularly in the domains of multimodal understanding and generation. Multimodal understanding involves machines comprehending and reasoning about information presented in different modalities, such as images and text.
Traditionally, these two areas have been addressed with separate, specialized models. However, a new trend is emerging — the unified multimodal model. Show-O, a groundbreaking AI model that shows the potential for a single transformer network to excel in both multimodal understanding and generation.
Keywords: Show-O AI, unified AI model, multimodal AI, AI image generation, AI understanding, next-generation AI, future of AI, AI research, AI applications.

The current Landscape of Multimodal AI
Before diving into Show-O, it’s crucial to understand the context of its development.
Multimodal Understanding: This field has witnessed the rise of powerful Multimodal Large Language Models (MLLMs) like LLaVA. These models excel at tasks such as visual question answering (VQA), where they are presented with an image and a question about its content, and must provide a textual answer. MLLMs typically leverage transformer architectures, renowned for their ability to process sequential data and capture long-range dependencies.
Multimodal Generation: Denoising diffusion probabilistic models (DDPMs) have revolutionized visual generation. These models excel at tasks like text-to-image generation, where they create realistic images from detailed text descriptions. DDPMs operate by gradually removing noise from an initially random image, guided by the provided text.
The Need for Unification?
While impressive individually, the separate development of understanding and generation models raises a natural question: can a single model master both?
“The only source of knowledge is experience.” — Albert Einstein
This quest for a unified model resonates with Einstein’s quote, as it suggests that a model trained on both understanding and generating multimodal data might gain a deeper, more holistic “experience” of the world it represents.
Show-O: A Unified Transformer Model
Show-O addresses above mentioned challenge by unifying autoregressive modeling (common in LLMs) with discrete diffusion modeling (inspired by DDPMs) within a single transformer network. This fusion allows Show-O to handle a wide range of multimodal tasks, from answering questions about images to generating images from text descriptions and even creating video keyframes with accompanying descriptions.
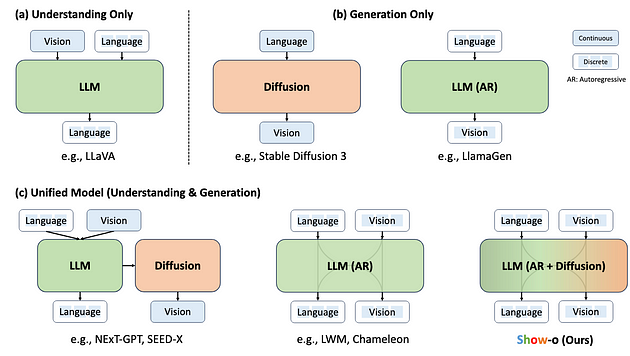
Model Architecture
Show-O’s architecture is based on pre-trained LLMs like Phi-1.5 and inherits their powerful text processing capabilities. To handle both text and images, Show-O operates on a unified vocabulary of discrete tokens.

Tokenization:
- Text Tokenization: Show-O uses the same tokenizer as its underlying LLM for processing text data.
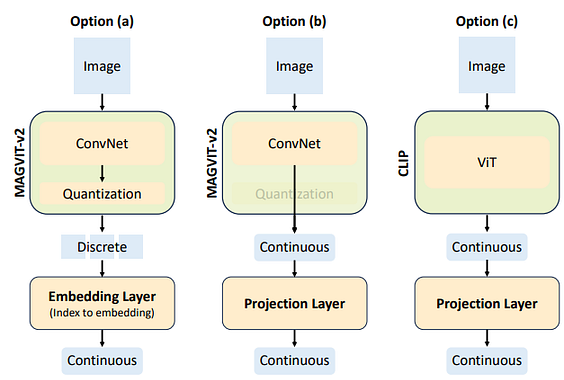
- Image Tokenization: Show-O employs a lookup-free quantizer trained on a large image dataset to convert images into discrete tokens. This approach is inspired by models like MAGVIT-v2, which demonstrate the effectiveness of discrete image representations.
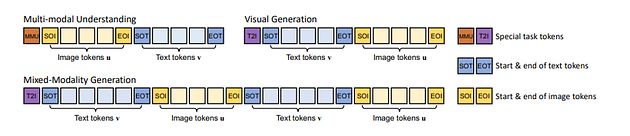
Unified Prompting:
A key innovation of Show-O is its unified prompting strategy. This strategy allows Show-O to process various multimodal inputs in a consistent, structured manner. For example, for a VQA task, the input sequence might be formatted as: [MMU] [SOI] image tokens [EOI] [SOT] question text [EOT]. Here, [MMU] signifies a multimodal understanding task, [SOI] and [EOI] denote the start and end of image tokens, and [SOT] and [EOT] mark the start and end of text tokens.
Omni-Attention Mechanism:
Show-O introduces a versatile attention mechanism called Omni-Attention. This mechanism dynamically adapts to the input sequence, using causal attention for text tokens (allowing them to attend only to preceding tokens) and full attention for image tokens (allowing them to attend to all other tokens). This allows Show-O to effectively leverage the strengths of both attention types for different modalities.

Show-O Training Objectives:
Show-O is trained with two primary objectives:
- Next Token Prediction (NTP): This objective, standard in language modeling, aims to predict the next token in a sequence given the preceding tokens. For multimodal understanding tasks, this involves predicting text tokens based on the context of both image and text tokens.
- Mask Token Prediction (MTP): This objective is inspired by discrete diffusion models. During training, a portion of image tokens are randomly masked, and the model is trained to predict the original values of these masked tokens based on the remaining tokens in the sequence.
Mathematical Formulation
The NTP objective is formulated as:LNTP = Σ log p(vi | v1, …, vi-1, u1, …, um; θ)
where:
- vi represents the i-th text token.
- v1, …, vi-1 are the preceding text tokens.
- u1, …, um are the image tokens.
- θ represents the model’s parameters.
- p(…) denotes the conditional probability of the i-th text token given the preceding tokens and the image tokens.
The MTP objective is formulated as:LMTP = Σ log p(uj | u1, …, u*, …, um, v1, …, vn; θ)
where:
- uj represents the j-th image token.
- u1, …, u*, …, um represents the sequence of image tokens with some tokens replaced by a mask token u*.
- v1, …, vn are the text tokens.
The overall training loss is a weighted combination of LNTP and LMTP:L = LMTP + α * LNT
where α is a hyperparameter controlling the relative importance of the two objectives.

What’s its Capabilities and Applications ?
Show-O’s unified architecture empowers it with a diverse range of capabilities:
- Multimodal Understanding: Show-O achieves comparable or even superior performance to specialized understanding models on benchmarks like VQA and image captioning.
- Visual Generation: Show-O demonstrates competitive text-to-image generation quality, rivaling dedicated diffusion models.
- Text-Guided Inpainting/Extrapolation: Show-O can seamlessly inpaint missing parts of an image or extrapolate its content based on text prompts, without requiring any fine-tuning.
- Mixed-Modality Generation: Show-O shows promise in generating interleaved sequences of text and images, opening up possibilities for applications like video keyframe generation with accompanying descriptions.

Getting Started
First, set up the environment:pip3 install -r requirments.txt
Download model weight of a pre-trained LLM (Phi-1.5):git lfs install
git clone https://huggingface.co/microsoft/phi-1_5
Download model weights of Show-o and put them to a directory in the structure below:├── checkpoints/
| ├── magvitv2.pth
| ├── showo.bin
| ├── showo_w_clip_vit.bin
| ├── phi-1_5
Login your wandb account on your machine or server.wandb login <your wandb keys>
Inference demo for Multimodal Understanding and you can view the results on wandb.python3 inference_mmu.py config=configs/showo_demo_w_clip_vit.yaml \
mmu_image_root=./mmu_validation question=’Please describe this image in detail. *** Do you think the image is unusual or not?’ \
pretrained_model_path=./checkpoints/showo_w_clip_vit.bin

Inference demo for Text-to-Image Generation and you can view the results on wandb.python3 inference_t2i.py config=configs/showo_demo.yaml \
batch_size=1 validation_prompts_file=validation_prompts/showoprompts.txt \
guidance_scale=1.75 generation_timesteps=18 \
mode=’t2i’ pretrained_model_path=./checkpoints/showo.bin

Inference demo for Text-guided Inpainting and you can view the results on wandb.python3 inference_t2i.py config=configs/showo_demo.yaml \
batch_size=1 \
guidance_scale=1.75 generation_timesteps=16 \
pretrained_model_path=./checkpoints/showo.bin \
mode=’inpainting’ prompt=’A blue sports car with sleek curves and tinted windows, parked on a bustling city street.’ \
image_path=./inpainting_validation/bus.jpg inpainting_mask_path=./inpainting_validation/bus_mask.webp

Inference demo for Text-guided Extrapolation and you can view the results on wandb.python3 inference_t2i.py config=configs/showo_demo.yaml \
batch_size=1 \
guidance_scale=1.75 generation_timesteps=16 \
pretrained_model_path=./checkpoints/showo.bin \
mode=’extrapolation’ extra_direction=’left *** left *** left *** right *** right *** right’ offset=0 prompt=’a serene natural landscape featuring a clear, blue lake surrounded by lush green trees. *** a serene natural landscape featuring a clear, blue lake surrounded by lush green trees. *** a serene natural landscape featuring a clear, blue lake surrounded by lush green trees. *** a serene natural landscape featuring a clear, blue lake surrounded by lush green trees. *** a serene natural landscape featuring a clear, blue lake surrounded by lush green trees. *** a serene natural landscape featuring a clear, blue lake surrounded by lush green trees.’ \
image_path=./inpainting_validation/alpine_lake.jpg
Impact and Future Directions
Show-O represents a significant step towards the development of truly versatile AI systems. Its ability to excel in both understanding and generating multimodal content paves the way for more sophisticated and creative AI applications.
“The key to artificial intelligence has always been the representation.” — Jeff Hawkins
Future research directions for Show-O and similar unified models include:
- Scaling: Exploring the impact of scaling model size and training data on performance.
- Long-Form Generation: Extending Show-O’s mixed-modality generation capabilities to create longer sequences of text and images, potentially leading to automated video generation.
- Fine-Grained Control: Developing techniques to provide users with finer control over the generated content, allowing for more personalized and specific outputs.
Conclusion
Show-O, a pioneering unified transformer, demonstrates the feasibility and potential of a single model mastering both multimodal understanding and generation. Its innovative architecture, incorporating discrete image representations, unified prompting, Omni-Attention, and dual training objectives, enables it to achieve remarkable performance across a variety of tasks. Show-O marks a significant advancement in the field of AI, offering a glimpse into a future where AI systems can seamlessly understand and create rich multimodal content.
Keywords: Show-O, unified transformer, multimodal understanding, multimodal generation, visual question answering, text-to-image generation, inpainting, extrapolation, mixed-modality generation, AI, artificial intelligence, deep learning, transformer networks, diffusion models, autoregressive models, discrete image representations, LLM, MLLM, DDPM, VQA.

What do you think about this article? Let me know in the comments.
#Show O
#Unified Ai Model
#Multimodal Ai
#AI
#Future Of Ai