
What is Imbalance Data?
Imbalanced data refers to a classification problem where the number of observations belonging to one class significantly outnumbers the number of observations belonging to the other classes. This can lead to a classifier that is biased towards the majority class, and can struggle to accurately identify instances of the minority class. Imbalanced data is a common problem in machine learning, and it can be addressed in a number of ways, including collecting more data for the minority class, undersampling the majority class, oversampling the minority class, or using algorithms specifically designed to handle imbalanced data.
Here’s an example of imbalanced data using Python’s scikit-learn library. We’ll start by generating some synthetic data for a binary classification problem with imbalanced classes.
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
# Generate synthetic data with imbalanced classes
X, y = make_classification(n_samples=10000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_clusters_per_class=1,
weights=[0.99, 0.01], flip_y=0, random_state=42)
# Plot the synthetic data
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='viridis')
plt.title('Imbalanced data')
plt.show()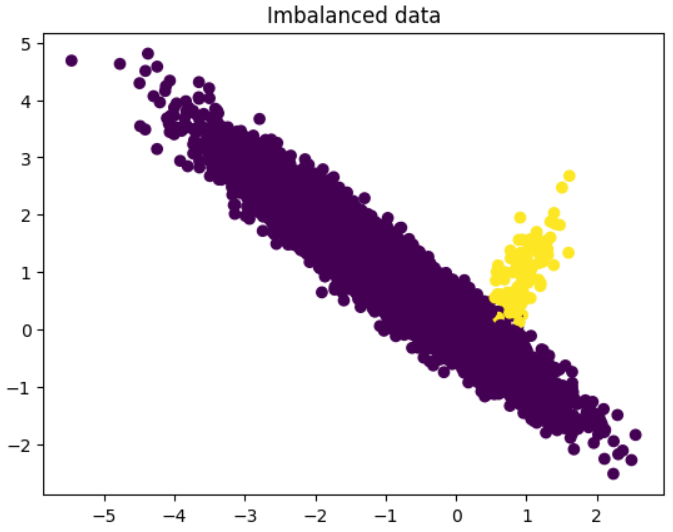
As you can see, there are many more observations belonging to the majority class (Purple) than the minority class (Yellow). This can cause problems when training a classifier, as the classifier may be biased towards the majority class and struggle to accurately classify instances of the minority class.
class imbalances are common in many real-world datasets and can present challenges for machine learning algorithms. In these cases, the majority class can dominate the training process and cause the model to perform poorly on the minority class. This can be particularly problematic in domains such as fraud detection or customer churn analysis, where correctly identifying instances of the minority class is often of high importance.
There are several approaches that can be taken to address class imbalances in a dataset. These can include techniques such as oversampling the minority class, undersampling the majority class, or using techniques such as weighting or adjusting the decision threshold to give more importance to the minority class. It is important to carefully consider the class imbalance in a dataset and choose an appropriate approach to address it in order to build a reliable and effective machine learning model.
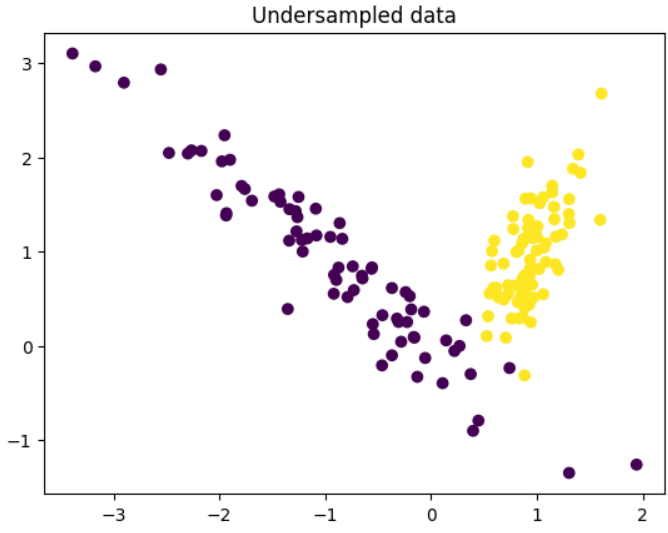
To address this problem, we can try undersampling the majority class or oversampling the minority class. Here’s an example of how to undersample the majority class using scikit-learn:from sklearn.model_selection import train_test_split
from imblearn.under_sampling import RandomUnderSampler
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Undersample the training data using random under-sampling
undersample = RandomUnderSampler(sampling_strategy=’majority’)
X_train_undersampled, y_train_undersampled = undersample.fit_resample(X_train, y_train)
# Plot the undersampled data
plt.scatter(X_train_undersampled[:, 0], X_train_undersampled[:, 1], c=y_train_undersampled, cmap=’viridis’)
plt.title(‘Undersampled data’)
plt.show()
Most Common Tactics to Combat Imbalanced Training Data
- Collect more data for the minority class: One of the most straightforward ways to address class imbalance is to simply collect more data for the minority class. This can help to balance the dataset and give the classifier more examples to learn from.
- Undersample the majority class: Another tactic is to undersample the majority class, which involves randomly removing observations from the majority class until the class distribution is balanced. This can be done using the
RandomUnderSamplerclass fromimblearn.under_sampling. Here’s an example of how to undersample the majority class in a binary classification problem:
from sklearn.model_selection import train_test_split
from imblearn.under_sampling import RandomUnderSampler
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Undersample the training data using random under-sampling
undersample = RandomUnderSampler(sampling_strategy='majority')
X_train_undersampled, y_train_undersampled = undersample.fit_resample(X_train, y_train)3.Oversample the minority class: Another tactic is to oversample the minority class, which involves randomly sampling with replacement from the minority class to create new artificial instances. This can be done using the RandomOverSampler class from imblearn.over_sampling. Here’s an example of how to oversample the minority class in a binary classification problem:
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import RandomOverSampler
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Oversample the training data using random over-sampling
oversample = RandomOverSampler(sampling_strategy='minority')
X_train_oversampled, y_train_oversampled = oversample.fit_resample(X_train, y_train)4.Use a different evaluation metric: When working with imbalanced data, it can be useful to use evaluation metrics that are less sensitive to class imbalance, such as precision, recall, or F1 score. For example, here’s how to compute the F1 score for a binary classification problem in scikit-learn
from sklearn.metrics
import f1_score
# Predict on the test set
y_pred = clf.predict(X_test)
# Compute the F1 score
f1 = f1_score(y_test, y_pred)
print(f'Test F1 score: {f1:.4f}')5.Use a different algorithm: Some machine learning algorithms are less sensitive to class imbalance than others. For example, decision tree algorithms are often less sensitive to class imbalance than logistic regression or support vector machines. It can be useful.
from sklearn.tree import DecisionTreeClassifier
# Train a decision tree classifier
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)There are many other algorithms that can be used to handle imbalanced data, such as k-nearest neighbors, random forests, and gradient boosting. It is often useful to try a few different algorithms and compare their performance on your dataset.
6. Use a cost-sensitive learning algorithm: Some machine learning algorithms can be made more sensitive to class imbalance by assigning different costs to the classes. For example, in scikit-learn, the LogisticRegression classifier has a class_weight parameter that can be used to assign higher costs to the minority class. Here’s an example of how to use the LogisticRegression classifier with class weights in a binary classification problem:
from sklearn.linear_model import LogisticRegression
# Train a logistic regression classifier with class weights
clf = LogisticRegression(class_weight='balanced', random_state=42)
clf.fit(X_train, y_train)7.Use a threshold-moving algorithm: Some machine learning algorithms, such as logistic regression, generate probabilities for each class. These probabilities can be used to adjust the classification threshold to make the classifier more sensitive to the minority class. For example, in scikit-learn, the LogisticRegression classifier has a predict_proba method that can be used to generate class probabilities. Here’s an example of how to use the class probabilities to adjust the classification threshold in a binary classification problem:
from sklearn.metrics import confusion_matrix
# Predict class probabilities on the test set
y_probs = clf.predict_proba(X_test)
# Select the positive class probabilities
y_probs = y_probs[:, 1]
# Set the classification threshold at 0.4
y_pred = (y_probs > 0.4).astype(int)
# Print the confusion matrix
confusion_matrix(y_test, y_pred)8. Use synthetic data generation techniques: Another tactic is to use synthetic data generation techniques to create new artificial instances of the minority class. These techniques involve generating synthetic samples that are similar to the minority class, but do not exactly match any of the existing observations. There are several methods for generating synthetic data, including over-sampling methods like SMOTE (Synthetic Minority Oversampling Technique) and ADASYN (Adaptive Synthetic Sampling). Here’s an example of how to use the SMOTE algorithm to generate synthetic data in a binary classification problem using imblearn.over_sampling:
from imblearn.over_sampling import SMOTE
# Oversample the training data using SMOTE
oversample = SMOTE(sampling_strategy='minority')
X_train_oversampled, y_train_oversampled = oversample.fit_resample(X_train, y_train)Note that synthetic data generation techniques can introduce additional complexity and may not always improve model performance. It is important to carefully evaluate the performance of a model trained on synthetic data to ensure that it is not overfitting to the synthetic samples.
Lets meet in Next Blog. Do follow me for more updates!

#Beginners Guide
#Imbalanced Data
#Artificial Intelligence
#Towards Data Science
#Machine Learning