
Dropout is a strategy used to mitigate overfitting in neural networks. It works by randomly deactivating a certain percentage of neurons in the network during each training update. This approach encourages the network to develop several independent representations of the data, as it cannot rely on any single set of neurons. Importantly, dropout is applied to the neurons in the hidden layers, not the input features, and can be implemented in any layer of the network. When the network is in testing or evaluation mode, all neurons are active. The specific proportion of neurons that are deactivated during training is controlled by a hyperparameter known as the dropout rate.
Dropout is a method designed to reduce overfitting in neural networks through a process of selectively deactivating neurons during training. Essentially, a predetermined percentage of neurons are randomly “turned off” by setting their outputs to zero at each step of the training process. This technique encourages the network to develop a more robust and less interdependent structure, as it cannot rely on specific neurons consistently. The result is that the network learns a variety of independent data representations, making it less prone to memorizing the training data and more effective at generalizing to new, unseen data. This random deactivation of neurons ensures that the network’s learning is distributed across a broader set of connections, enhancing its ability to generalize.
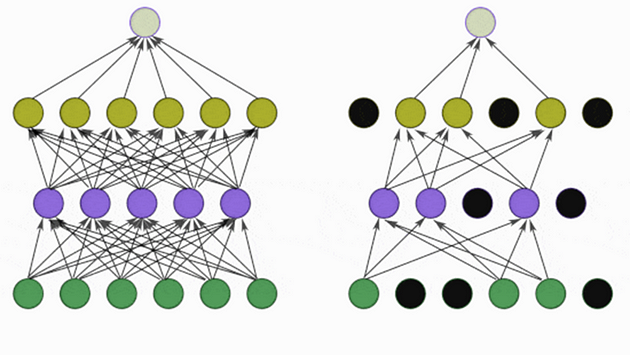
The dropout rate, often represented as a decimal between 0 and 1, is a hyperparameter that determines the percentage of neurons to drop out during training. For example, a dropout rate of 0.2 would drop out 20% of the neurons at each training step.
When dropout is applied to a layer, for each training example, each neuron in the layer has a probability of being “dropped out” or set to zero. This is done by applying a binary mask to the input, where each element in the mask is set to 1 with probability of 1-p or 0 with probability p, where p is the dropout rate. The mask is applied element-wise to the input, effectively setting a random subset of the input to zero. This mask is different for each training example, and therefore the output of the dropout layer is also different for each training example.
During the evaluation or testing phase, dropout is not used, all neurons are used to make predictions. This is because dropout is only used during training to prevent overfitting, and during testing, it is assumed that the network has already learned to generalize to unseen data.
Let’s see an example of how to add dropout to a fully connected layer in Keras, a popular deep learning framework in python:
from keras.layers import Dropout
# Define the model
model = Sequential()
# Add a fully connected layer with dropout
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
# Add more layers as needed
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))In this example, the Dropout layer is added after the first fully connected (Dense) layer with a dropout rate of 0.5, which means that 50% of the neurons in that layer will be dropped out during training. This is done by applying a binary mask to the input, where each element in the mask is set to 1 with probability of 1-p or 0 with probability p, where p is the dropout rate.
The dropout rate is a hyperparameter that determines the percentage of neurons to drop out during training. The optimal dropout rate will depend on the specific architecture of the network, the amount and quality of the training data, and the task at hand.
A common dropout rate is 0.2 or 0.5, which means that 20% or 50% of the neurons will be dropped out during training, respectively. However, it’s worth noting that dropout rate is a hyperparameter that needs to be experimentally determined. It’s a good idea to start with a relatively low dropout rate (e.g. 0.1 or 0.2) and gradually increase it until a satisfactory level of performance is achieved.
Dropout rate of more than 50% will make your network not learn anything as the majority of the neurons are dropped out and the network will not be able to make predictions. It also will not give a good generalization and will not be able to make predictions on unseen data.
There are several ways to visualize the effect of dropout on a neural network. One common way is to visualize the activation maps of the neurons in a network before and after applying dropout. Activation maps show the areas of an input image that are most important for a given neuron to fire. When dropout is applied, some neurons will be randomly turned off, which can affect the activation maps.
Another way to visualize the effect of dropout is to train a network with and without dropout and compare the learned filters (weights) of the convolutional layers. With dropout, the filters will be less sensitive to specific patterns in the input data, which can be visualized by looking at the learned filters.
You can also visualize the effect of dropout on the network’s accuracy, loss and other performance metrics. One way to do this is to train a network with different dropout rates and compare the performance of the network across different dropout rates.
I couldn’t find any visual representation on the internet to show you, but I hope this gives you an idea of the ways dropout can be visualized.
Keep in mind that dropout is a technique that tries to prevent overfitting, and while visualization can be helpful in understanding its effects, the most important thing is to evaluate the performance of the network on unseen data.
Applications
Dropout is a widely used regularization technique in deep learning and has been applied in a variety of real-world applications. Some examples include:
- Computer Vision: Dropout has been used in many state-of-the-art convolutional neural networks (CNNs) for image classification tasks. It has been shown to be particularly effective in preventing overfitting when applied to the fully connected layers of a CNN.
- Natural Language Processing: Dropout has been used in many deep learning models for natural language processing tasks such as language translation, text classification, and sentiment analysis.
- Speech Recognition: Dropout has been used in deep learning models for speech recognition tasks, such as automatic speech recognition (ASR) systems.
- Recommender Systems: Dropout has been used in deep learning models for recommendation systems, such as those used in recommendation engines for e-commerce websites and streaming services.
- Healthcare: Dropout has been used in deep learning models for healthcare applications, such as medical image analysis and drug discovery.
These are just a few examples of the many ways that dropout has been used in real-world applications. The effectiveness of dropout may vary depending on the specific task and the architecture of the network, but it is a widely used technique in deep learning and has been shown to be effective in preventing overfitting in many applications.

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
#Deep Learning
#Machine Learning
#Beginners Guide
#Data Science
#Naturallanguageprocessing